贾里尼克从来不是真正的计算机科学家,而他的专长是信息论和通信,因此他看待语音识别问题完全不同于人工智能的专家们--在他看来这是一个通信问题。人的大脑是一个信息源,从思考到合适的语句,再通过发音说出来,是一个编码的过程,经过媒介(空气或者电话线)传播到听众耳朵里,是经过了一个长长的信道的信息传播问题,最后听话人把它听懂,是一个解码的过程。既然是一个典型的通信问题,就可以用解决通信问题的方法来解决,为此贾里尼克用两个马尔可夫模型分别描述信源和信道。当然,为了训练和使用这两个马尔可夫模型,就需要使用大量的数据。采用马尔可夫模型,IBM 将当时的语音识别率从70%左右提高到90%以上,同时语音识别的规模从几百词上升到两万多词 (Jelinek, 1976),这样,语音识别就能够从实验室走向实际应用。 贾里尼克和他的同事在无意中开创了一种采用统计的方法解决智能问题的途径,因为这种方法需要使用大量的数据,因此它又被称为是数据驱动的方法。
贾里尼克的同事彼得∙布朗在1980年代,将这种数据驱动的方法用于了机器翻译 (P.F. Brown, 1990)。由于缺乏数据,最初的翻译结果并不令人满意,虽然一些学者认可这种方法,但是其他学者,尤其是早期从事这项工作的学者认为,解决机器翻译这样智能的问题,光靠基于数据的统计是不够的。因此,当时SysTran等公司依然在组织大量的人力,写机器翻译使用的语法规则。
如果说在1980年代还看不清楚布朗的方法和传统的人工智能的方法哪一个更适合计算机解决机器智能问题的话,那么在1990年代以后,数据的优势就凸显出来了。从1990年代中期之后的10年里,语音识别的错误率减少了一半,而机器翻译的准确性提高了一倍,其中20%左右的贡献来自于方法的改进,而80%则来自于数据量的提升。当然,这背后的一个原因是,由于互联网的普及,可使用的数据量呈指数增长。
最能够说明数据对解决机器翻译等智能问题的帮助的,是2005年NIST对全世界各家机器翻译系统评测的结果。
这一年,之前没有做过机器翻译的Google,不仅一举夺得了各项评比的第一名,而且将其它单位的系统远远抛在了后面。比如在阿拉伯语到英语翻译的封闭集测试中,Google系统的BLEU评分为51.31%,领先第二名将近 5%,而提高这五个百分点在过去需要研究7—10年;在开放集的测试中,Google51.37%的得分比第二名领先了17%,可以说整整领先了一代人的水平。当然,大家能想到的原因是它请到了世界著名的机器翻译专家弗朗兹·奥科(Franz Och),但是参加评测的南加州大学系统和德国亚琛工学院系统也是奥科写的姊妹系统。从奥科在Google开始工作到提交评比结果,中间其实只有半年多的时间,奥科在方法上没有做任何改进。Google系统和之前的两个系统唯一的不同之处在于,前者使用了后者近万倍的数据量。
下表是2005年NIST评比的结果。值得一提的是,SysTran公司的系统是唯一采用传统的语法规则进行机器翻译的。它和那些采用数据驱动的系统相比,差距之大已经不在一个时代了。
从阿拉伯语到英语的翻译 (封闭集)
Google 51.31%
南加州大学 46.57%
IBM沃森实验室 46.46%
马里兰大学 44.97%
约翰∙霍普金斯大学 43.48%
……
SYSTRAN公司 10.79%
从中文到英语翻译 (开放集)
Google 51.37%
SAKHR公司 34.03%
美军ARL研究所 22.57%
表1 2005年NIST对全世界多种机器翻译系统进行评比的结果
到了2000年之后,虽然还有一些旧式的学者死守着传统人工智能的方法不放,但是无论是学术界还是工业界,机器智能的主流方法是基于统计或者说数据驱动的方法。与此同时,另外两个相关的研究领域,机器学习和数据挖掘也开始热门起来。
2012-2014年,笔者曾经负责Google的机器问答项目,并且通过使用大数据,解决了30%左右的问题,这远远超过了学术界迄今为止同类研究的水平。究其原因,除了Google在自然语言处理等基础算法上做到了世界领先之外,更重要的是,Google将这个过去认为是存粹自然语言理解的问题变成了一个大数据的问题。首先,Google发现对于用户在互联网上问的各种复杂问题,有70-80%左右的问题可以在前十条自然搜索结果(去掉广告、图片和视频等结果)中找到答案,而只有20%左右的复杂问题,答案存在于搜索结果的摘要里。因此,Google将机器自动问答这样一个难题转换成了在大数据中寻找答案的摘要问题。当然,这里面有三个前提,首先答案需要存在,这就是我们前面讲到的大数据的完备性;其次,计算能力需要足够,Google回答这样一个问题的时间小于10毫秒,但是需要上万台服务器同时工作;最后,就是要用到非常多的自然语言处理算法,包括对全部的搜索内容要进行语法分析和语义分析,要能够从文字的片段合成符合语法而且读起来通顺的自然语言等等。其中第一个前提是只有Google等少数大公司具备,而学术界不具备,因此这就决定了是Google而非学术界最早解决图灵留下的这个难题。
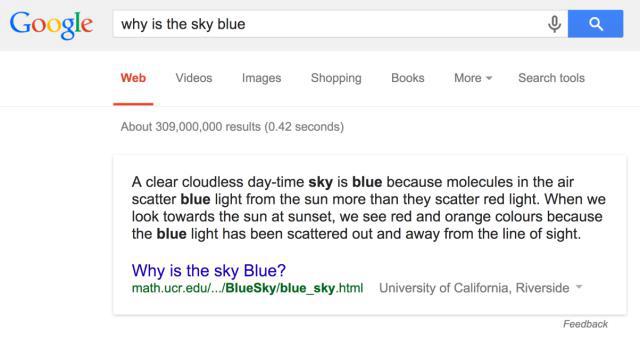
图 3 Google自动问答(问题为“天为什么是蓝色的?”,问题下面是计算机产生的答案)
由此可见,我们对数据重要性的认识不应该停留在统计、改进产品和销售,或者提供决策的支持上,而应该看到它(和摩尔定律、数学模型一起)导致了机器智能的产生。而机器一旦产生了和人类类似的智能,就将对人类社会产生重大的影响了。
转载请注明:北纬40° » 大数据、机器智能和未来社会的图景



